
A revolutionary new architecture aims to make the internet more “social” by eliminating the need to connect to servers and enabling all content to be shared more efficiently.
A revolutionary new architecture aims to make the internet more “social” by eliminating the need to connect to servers and enabling all content to be shared more efficiently.
One colleague asked me how, using this architecture, you would get to the server. The answer is: you don’t.
Dirk Trossen
Researchers have taken the first step towards a radical new architecture for the internet, which they claim will transform the way in which information is shared online, and make it faster and safer to use.
The prototype, which has been developed as part of an EU-funded project called “Pursuit”, is being put forward as a proof-of concept model for overhauling the existing structure of the internet’s IP layer, through which isolated networks are connected, or “internetworked”.
The Pursuit Internet would, according to its creators, enable a more socially-minded and intelligent system, in which users would be able to obtain information without needing direct access to the servers where content is initially stored.
Instead, individual computers would be able to copy and republish content on receipt, providing other users with the option to access data, or fragments of data, from a wide range of locations rather than the source itself. Essentially, the model would enable all online content to be shared in a manner emulating the “peer-to-peer” approach taken by some file-sharing sites, but on an unprecedented, internet-wide scale.
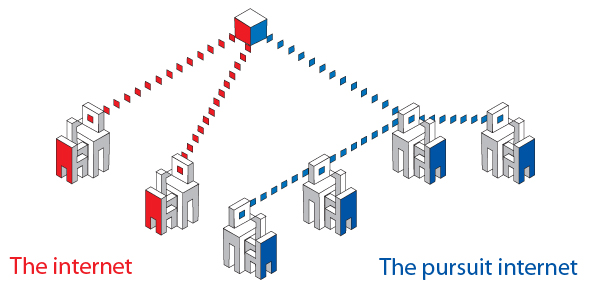
That would potentially make the internet faster, more efficient, and more capable of withstanding rapidly escalating levels of global user demand. It would also make information delivery almost immune to server crashes, and significantly enhance the ability of users to control access to their private information online.
While this would lead to an even wider dispersal of online materials than we experience now, however, the researchers behind the project also argue that by focusing on information rather than the web addresses (URLs) where it is stored, digital content would become more secure. They envisage that by making individual bits of data recognisable, that data could be “fingerprinted” to show that it comes from an authorised source.
Dr Dirk Trossen, a senior researcher at the University of Cambridge Computer Lab, and the technical manager for Pursuit, said: “The current internet architecture is based on the idea that one computer calls another, with packets of information moving between them, from end to end. As users, however, we aren’t interested in the storage location or connecting the endpoints. What we want is the stuff that lives there.”
“Our system focuses on the way in which society itself uses the internet to get hold of that content. It puts information first. One colleague asked me how, using this architecture, you would get to the server. The answer is: you don’t. The only reason we care about web addresses and servers now is because the people who designed the network tell us that we need to. What we are really after is content and information.”
In May this year, the Pursuit team won the Future Internet Assembly (FIA) award after successfully demonstrating applications which can, potentially, search for and retrieve information online on this basis. The breakthrough raises the possibility that almost anybody could identify specific pieces of content in fine detail, radically changing the way in which information is stored and held online.
For example, at the moment if a user wants to watch their favourite TV show online, they search for that show using a search engine which retrieves what it thinks is the URL where that show is stored. This content is hosted by a particular server, or, in some cases, a proxy server.
If, however, the user could correctly identify the content itself – in this case the show – then the location where the show is stored becomes less relevant. Technically, the show could be stored anywhere and everywhere. The Pursuit network would be able to map the desired content on to the possible locations at the time of the desired viewing, ultimately providing the user with a list of locations from which that information could be retrieved.
The designers of Pursuit hope that, in the future, this is how the internet will work. Technically, online searches would stop looking for URLs (the Uniform Resource Locator) and start looking for URIs (Uniform Resource Identifiers). In simple terms, these would be highly specific identifiers which enable the system to work out what the information or content is.
This has the potential to revolutionise the way in which information is routed and forwarded online. “Under our system, if someone near you had already watched that video or show, then in the course of getting it their computer or platform would republish the content,” Trossen explained. “That would enable
you to get the content from their network, as well as from the original server.”
“Widely used content that millions of people want would end up being widely diffused across the network. Everyone who has republished the content could give you some, or all of it. So essentially we are taking dedicated servers out of the equation.”
Any such system would have numerous benefits. Most obviously, it would make access to information faster and more efficient, and prevent servers or sources from becoming overloaded. At the moment, if user demand becomes unsustainable, servers go down and have to be restored. Under the Pursuit model, demand would be diffused across the system.
“With a system like the one we are proposing, the whole system becomes sustainable,” Trossen added. “The need to do something like this is only going to become more pressing as we record and upload more information.”
Further information about the PURSUIT project can be found at: http://www.fp7-pursuit.eu/
For more information about this story, please contact Tom Kirk, Tel: +44 (0)1223 332300, thomas.kirk@admin.cam.ac.uk

This work is licensed under a Creative Commons Licence. If you use this content on your site please link back to this page.



