Computational biology is helping scientists to navigate through the data deluge generated from the analysis of cancer genomes.
Computational biology is helping scientists to navigate through the data deluge generated from the analysis of cancer genomes.
The advent of new technologies has enabled researchers to interrogate human genomes at unprecedented resolution. These technologies have led to a wealth of genomic information that has the capacity to shed new light on complex diseases, but they also generate far too much data to interpret by eye. Consequently, novel computational and statistical techniques have evolved to extract meaningful patterns from the data (‘data mining’) and to integrate this with other types of biological information in an attempt to make sense of what it all means.
In Cambridge, a collaboration between the Computational Biology group at the Cancer Research UK Cambridge Research Institute (CRI), led by Professor Simon Tavaré (also at the Department of Applied Mathematics and Theoretical Physics), and Professor Carlos Caldas and Dr James Brenton (who are both at the CRI and the Department of Oncology) seeks to do just this, demonstrating the power of combining expertise in statistics, computational and experimental biology, and clinical medicine to understand cancer.
METABRIC
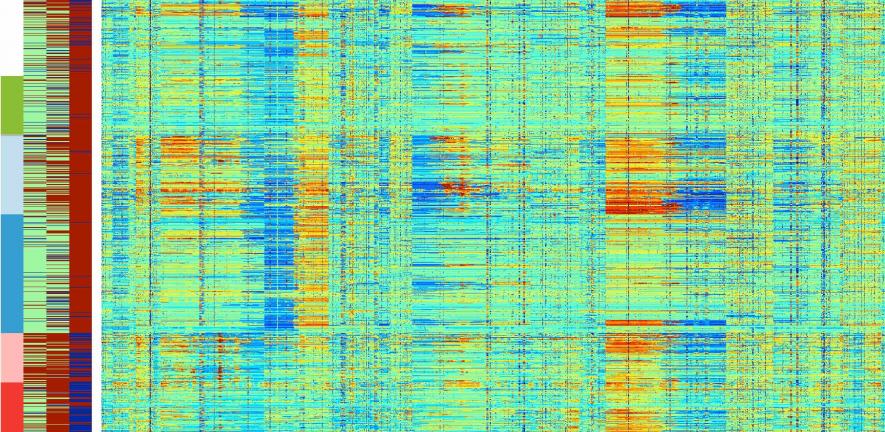
Breast cancer, like other malignancies, is driven by the progressive acquisition of key genetic alterations that confer growth advantages on the cell. Most of the acquired aberrations are merely ‘passenger’ events that do not influence cancer progression, whereas the ‘driver’ events are critical mediators of disease. It is these ‘driver’ events and the effects they elicit that researchers seek to identify, the problem being akin to searching for a needle in a haystack.
METABRIC (Molecular Taxonomy of Breast Cancer International Consortium) is an Anglo-Canadian effort aimed at finding the ‘needles’, and is funded by Cancer Research UK and the British Columbia Cancer Foundation. Given the substantial molecular heterogeneity among breast cancer patients, METABRIC seeks to interrogate the genomic and transcriptional landscape of over 2,000 clinically annotated breast tumour specimens to generate a robust molecular description of the disease.
Each sample is examined for differences in gene expression levels, as well as for alterations in the number of copies of each gene, by combining measurements from nearly two million probes that query the genome at sequential positions. Add to this a variety of other data types and five years of clinical history, and you wonder how the sheer volume of data can be processed,
let alone interpreted. In fact, a major challenge with such high-dimensional datasets is the identification of true differences amid inherent background noise. How can one see the forest for the trees in the cancer genome landscape?
Seeing the forest for the trees
Dr Christina Curtis in the Computational Biology group is leading the analysis of massively parallel technologies using computational and statistical methods to make sense of this vast data deluge. Much of her research relies on high-performance computing to process these and other large datasets. Fortunately, the CRI houses a computer cluster with nearly 500 cores and multiple high-memory nodes that will expand to meet the growing need for computational capacity.
Using novel analytical approaches for data integration and mining, Dr Curtis and her team have defined additional subtypes of breast cancer based on their unique molecular characteristics, providing fresh insight into mechanisms of breast cancer tumourigenesis. Future work will relate these molecular profiles to specific clinical phenotypes and identify markers that improve the classification of breast cancer. Importantly, the techniques employed for METABRIC are sufficiently general to be applied to a variety of other cancer datasets.
Computational biology is providing the means to navigate through large-scale, multi-dimensional datasets. In doing so, it can help to build a holistic, systems-level perspective on cancer that will shape future clinical practice.
For more information, please contact Professor Simon Tavaré (st321@cam.ac.uk) and Dr Christina Curtis (cc529@cam.ac.uk) at the Cancer Research UK Cambridge Research Institute/Li Ka Shing Centre.

This work is licensed under a Creative Commons Licence. If you use this content on your site please link back to this page.



